
Enhancing Media Enrichment by Semantic Extraction
Authors: Michael Krug, Fabian Wiedemann, Martin Gaedke
Introduction
 The opportunities of the Internet combined with new devices and technologies change the end users’ habits in media consumption. While end users often search for related information to the currently watched TV show by themselves, we propose to improve this user experience by automatically enriching media using semantic extraction. In our recent work we focused on how to apply media enrichment to distributed screens. Based on the findings we made from our recent prototype we identify several problems and describe how we deal with them. We illustrate a way to achieve cross-platform real-time synchronization using several transport protocols. We propose the usage of sessions to handle multi-user, multi-screen scenarios and introduce techniques for new interaction and customization patterns. We extend our recent approach with the extraction of keywords from given subtitles by utilizing statistical algorithms and natural language processing technologies, which are then used to discover and display related content from the Web. The prototype presented in this paper reflects the improvements of our work. We discuss next research steps and define challenges for further research.
The opportunities of the Internet combined with new devices and technologies change the end users’ habits in media consumption. While end users often search for related information to the currently watched TV show by themselves, we propose to improve this user experience by automatically enriching media using semantic extraction. In our recent work we focused on how to apply media enrichment to distributed screens. Based on the findings we made from our recent prototype we identify several problems and describe how we deal with them. We illustrate a way to achieve cross-platform real-time synchronization using several transport protocols. We propose the usage of sessions to handle multi-user, multi-screen scenarios and introduce techniques for new interaction and customization patterns. We extend our recent approach with the extraction of keywords from given subtitles by utilizing statistical algorithms and natural language processing technologies, which are then used to discover and display related content from the Web. The prototype presented in this paper reflects the improvements of our work. We discuss next research steps and define challenges for further research.
Demo
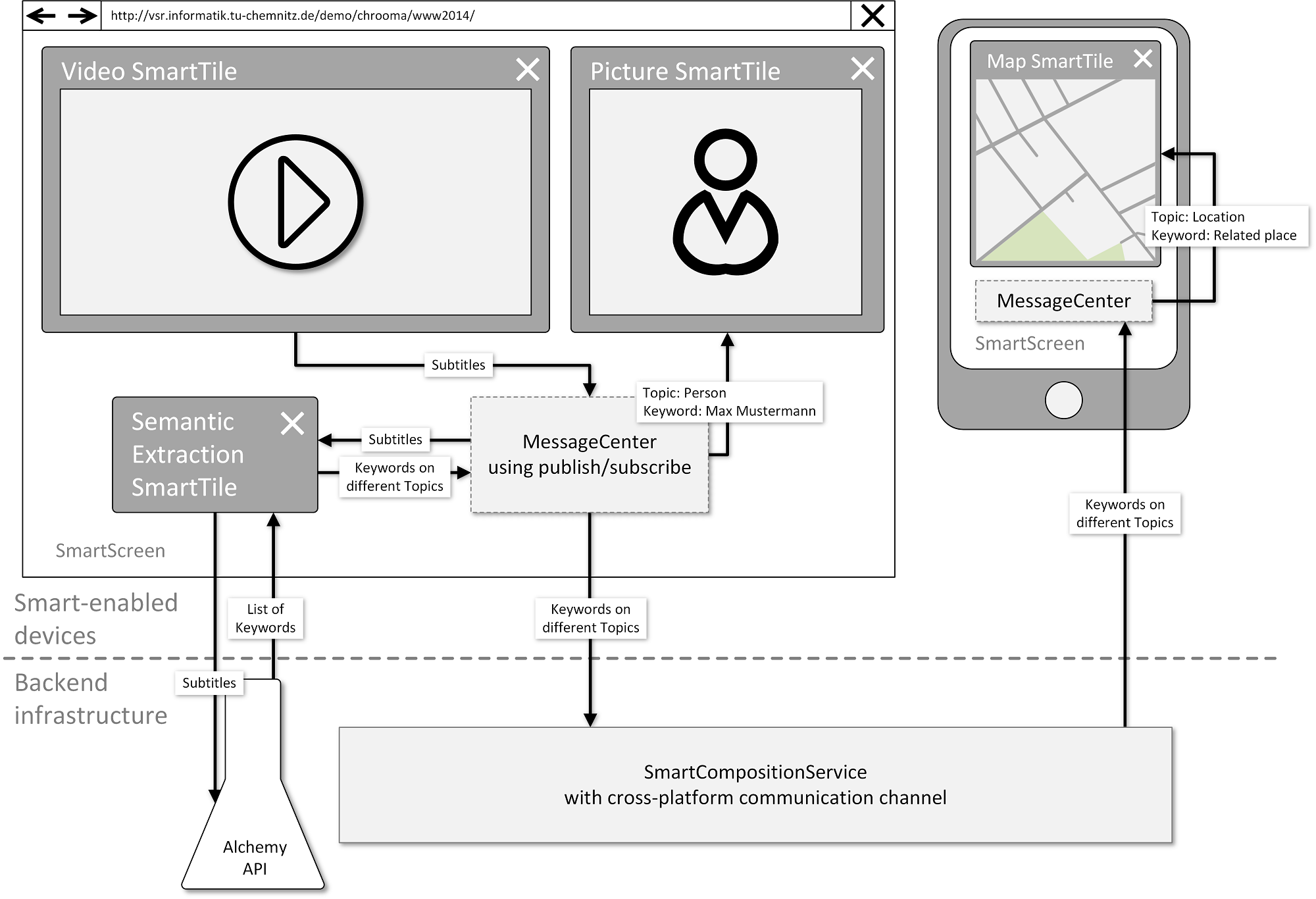
Our demo presents an example workspace for automatically enrich media using semantic extraction. We show a video tile that plays a German newscast. The video has German transcriptions in the WebVTT format attached. Next to the video tile there are a few other kinds of SmartTiles that will present related information from the Web as well as some tiles that are used as intermediate components in the enrichment process. Since the video provides German subtitles and we currently support English text only, the subtitles get translated by a translate tile, which will then publish the text in the translated form. The English text is received and processed by the semantic extraction SmartTile. The results of the semantic extraction - keywords that are published on different topics - are displayed in different representations, as there are SmartTiles for displaying maps, images, tweets or articles. The user can rearrange the workspace, add or remove SmartTiles and can join multiple screens to a shared session. Within the session the events are synchronized and the user can exchange SmartTiles between the screens. An architectural overview of this demonstration is depicted in Figure 1.
To show that and how our approach and demonstrator works with different videos and subtitles, we integrate a special YouTube connection. The user is able to add a video from YouTube using the URL or ID of the video. The ID is used to get the URLs of the actual video streams, which are added as the source attribute for the HTML5 video tag. Since we rely on given subtitles or annotation, the YouTube video has to have closed captions. Those videos can be found by setting a filter on the YouTube search page. Our approach uses WebVTT files to synchronize the annotations with the playing video. YouTube does not offer the subtitles in this format. Therefore, we provide a Web service that transforms the closed captions from YouTube into the standardized WebVTT format. It uses a simple grouping algorithm to join single text lines into larger blocks. The service is also capable of the automatic translation of the subtitles. Since the service is directly responding the WebVTT structure, we can use the URL of the service as the source attribute of the text track element in the video tag. After the video is added to the SmartScreen and the metadata is loaded, the semantic extraction process described above is performed.
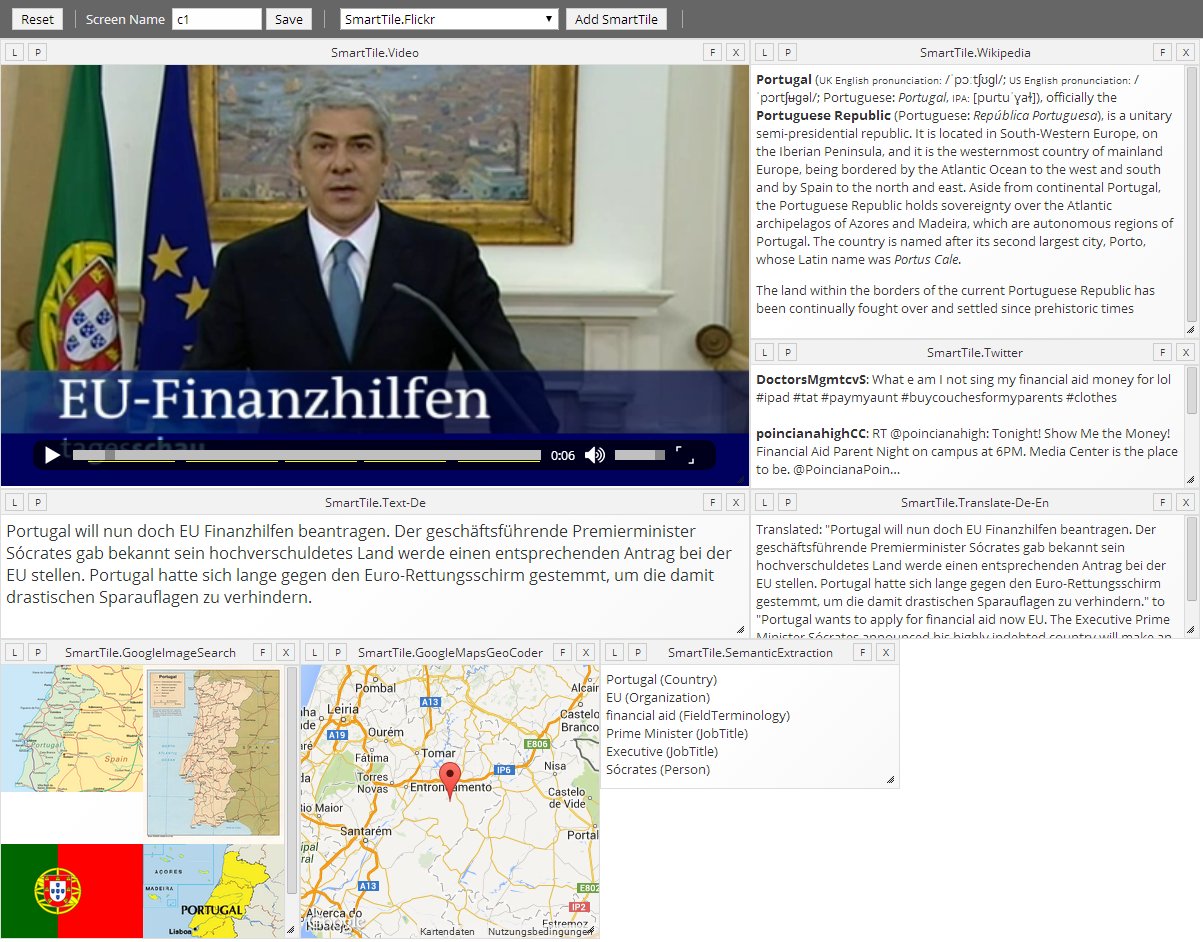
Demo page for larger displays
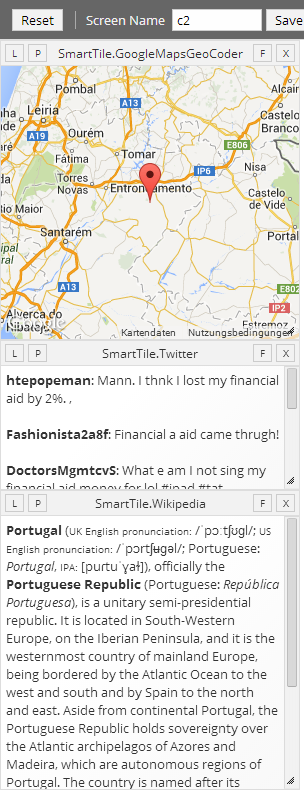
Demo page for smaller displays
Browser Support
The prototype is supported by the following browsers:
- Google Chrome 18+
- Firefox 11+
- Internet Explorer 10
- Opera 12.1+
- Safari 6+
- Google Chrome on Android