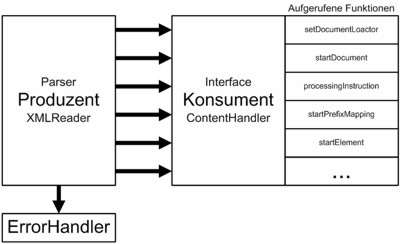
SAX besteht hauptsächlich aus 2 Komponenten: dem Produzenten und dem Konsumenten. Der Produzent ("XMLReader") stellt den Parser dar und versorgt den Konsumenten ("ContentHandler") mit den Informationen aus dem XML-Dokument, indem dessen Methoden aufgerufen werden.
|
| Abb. 4.1 Struktur von SAX |
Wenn der Produzent Ungereimtheiten in Wohlgeformtheit und Gültigkeit findet, kann der ErrorHandler diese verarbeiten.
Der Produzent ist eine Abstraktion des echten XML-Parsers und wird in SAX als
"XMLReader" bezeichnet. Er stellt neben den Methoden zum Parsen des
Dokumentes auch die Möglichkeit bereit, den Parser zu konfigurieren. So
kann man zum Beispiel die Gültigkeitüberprüfung aktivieren und
deaktivieren.
Erstellt wird eine Instanz des XMLReader mithilfe der Klasse XMLReaderFactory
aus dem Paket "org.xml.sax.helpers".
import org.xml.sax.*
import org.xml.sax.helpers.*
public class ProduzentBsp {
public static void main(String[] args){
try {
XMLReader parser = XMLReaderFactory.createXMLReader(
"org.apache.xerces.parsers.SAXParser");
}
catch (SAXException e) {
//Fehler beim Erzeugen des XMLReader
}
}
}
Abb. 4.2 Erstellung einer Instanz des XMLReader in Java
In Beispiel 4.2 werden zuerst die Pakete "org.xml.sax.*"
und "org.xml.sax.helpers.*" importiert
und dann wird mithilfe von "XMLReaderFactory.createXMLReader"
eine Instanz des XMLReader erstellt. Dabei wird der Funktion ein optionaler
Parameter übergeben, der den Parser angibt.
Schlägt das Erstellen fehl, weil zum Beispiel der Parser nicht installiert
ist, dann wird eine Exception vom Typ "SAXException"
ausgelöst.
Der Parser kann mithilfe der Funktion "setFeature"
der XMLReader-Instanz konfiguriert werden.
Die Funktion wir dabei mit zwei Parametern aufgerufen:
-Feature-Name als URI (z.B.: "http://xml.org/sax/features/validation")
-Boolescher Wert (true oder false) zum aktivieren bzw. deaktivieren
Der aktuelle Status eines Feature kann mit "getFeature"
der XMLReader-Instanz abgerufen werden. Die Funktion wird dabei mit dem Feature-Name
als Parameter aufgerufen und liefert einen booleschen Wert zurück.
try {Abb. 4.3 Beispiel zur Konfiguration des Parsers
parser.setFeature( "http://xml.org/sax/features/validation",true);
}
catch (SAXNotSupportedException e) {
//Validierung kann momentan nicht aktiviert werden
}
catch (SAXNotRecognizedException e) {
//Parser unterstützt Validierung nicht
}
In Beispiel 4.3 wird versucht das Feature zur Gültigkeitsüberprüfung
zu aktivieren. Dabei wird der Funktion "setFeature"
die URI "http://xml.org/sax/features/validation"
und der Wert "true" übergeben.
Da nicht alle Parser jedes Feature zu jeder Zeit unterstützen, kann es
zu Exceptions kommen. Die Exception "SAXNotRecognizedException"
wird ausgelöst, falls der Parser das Feature nicht unterstützt. "SAXNotSupportedException"
erhält man, falls das Feature momentan nicht aktiviert werden kann, so
kann zum Beispiel das Feature zur Güligkeitsüberprüfung nur vor
einem Parsing-Vorgang aktiviert werden.
Den Verarbeitungsvorgang startet man mit dem Aufruf der Funktion "parse",
die als Parameter die absolute oder relative URL des XML-Dokuments erwartet.
try { Abb. 4.4 Beispiel zum Starten des Parsens
parser.parse("http://www.beispiel.com/bsp.xml");
}
catch (SAXParseException e) {
//Fehler: Das Dokument ist nicht wohlgeformt
}
Sollte ein Dokument nicht wohlgeformt und so nicht verarbeitbar sein, so wird
die Exception "SAXParseException" ausgelöst.
Bei dem Konsumenten handelt es sich um das Interface "ContentHandler"
und wird vom Anwender selbst implementiert. Die implementierten Methoden werden
während des Parsens vom XMLReader aufgerufen.
Davor muss der ContentHandler dem XMLReader mitgeteilt werden.
Bsp.:
parser.setContentHandler(new MyContentHandler());
Methode setDocumentLocator(Locator locator)
locator: Lokator für Fehlerdiagnose (enthält
während des Parsens u.a. aktuelle Zeile und Spalte)
Ist der erste Aufruf des Parsers und kann keine Exception verursachen.
Methode startDocument()
Wird ohne Parameter beim Starten des Parsens aufgerufen und dann meist zum Initialisieren
von Variablen verwendet.
Methode endDocument()
Wird ohne Parameter beim Beenden des Parsens aufgerufen und dann meist zum Freigeben
nicht mehr benötigter Ressourcen genutzt.
Methode processingInstruction(String target, String
data)
target: Ziel der Verarbeitung (hier: "php")
data: Die restlich Daten (hier: "echo
'Hallo'; ")
Wird aufgerufen, wenn eine Verarbeitungsanweisung gefunden wird (z.B.: "<?php
echo 'Hallo'; ?>").
Methode startPrefixMapping(String prefix, String namespaceURI)
prefix: Präfix des Namensraumes
namespaceURI: Die zum Namensraum gehörende
URI
Wird aufgerufen, wenn eine Namensraumdeklaration auftaucht.
Methode startElement(String namespaceURI, String localName,
String qualifiedName, Attributes att)
namespaceURI: URI des Namensraumes
localName: Name des Elements ohne evt. Präfix
qualifiedName: Name des Elements mit evt. Präfix
att: Attribute des Elementes als Objekt
Zugriff direkt über den Namen des Attributes oder iterativ wie bei einem
Feld.
Bsp. (iterativ):
for (int i = 0; i < att.getLength(); i++) { Ein Element beginnt.
String uri = att.getURI(i); //Namensraum-URI
String localName = att.getLocalName(i); //Attributname
String value = att.getValue(i); //Attributwert
/* ... */
}
Methode endElement(String namespaceURI, String localName,
String qualifiedName)
namespaceURI: URI des Namensraumes
localName: Name des Elements ohne evt. Präfix
qualifiedName: Name des Elements mit evt. Präfix
Ein Element endet. Wird auch aufgerufen, wenn das Element leer ist (z.B.: "<leer
/>").
Methode endPrefixMapping(String prefix)
prefix: Präfix des Namensraumes
Wird aufgerufen, wenn eine Namensraumdeklaration nicht mehr auftaucht und folgt
immer auf einen "endElement"-Aufruf.
Methode characters(char[] ch, int start, int length)
ch: Textteil aus XML-Dokument, in dem die gefundenen
Zeichendaten enthalten sind
start: Anfang der gefundenen Zeichendaten
length: Länge der gefundenen Zeichendaten
Zeichendaten (CDATA) werden gefunden. Was "ch"
enthält, ist nicht eindeutig festgelegt und kann sich von Parser zu Parser
unterscheiden. Deterministisch ist nur, dass "start"
und "length" die richtige Position der
Zeichendaten angibt.
Methode ignorableWhitespace(char[] ch, int start, int
length)
ch: Textteil aus XML-Dokument, in dem die gefundenen
Leerzeichen enthalten sind
start: Anfang der gefundenen Leerzeichen
length: Länge der gefundenen Leerzeichen
Vernachlässigbarer Leerraum wird gefunden (zum Beispiel Zeilenumbruch oder
Einrückung). Was "ch" enthält,
ist nicht eindeutig festgelegt und kann sich von Parser zu Parser unterscheiden.
Deterministisch ist nur, dass "start"
und "length" die richtige Position der
Leerzeichen angibt.
Methode skippedEntity(String name)
name: Name der Entity (hier: „header“)
Parser hat eine Entity (z.B.: „&header;“)
gefunden, die er nicht zuordnen konnte (z.B. weil nicht oder extern deklariert).
Falls auch externe Entity-Deklarationen berücksichtigt werden sollen, gibt
es die Features “http://xml.org/sax/features/external-general-entities“
und „http://xml.org/sax/features/external-parameter-entities“.
Ein Filter wird zwischen XMLReader und ContentHandler zwischengeschaltet und kann Nachrichten einfach durchleiten, diese ändern, ersetzen oder blockieren. Dazu wird die Klasse XMLFilterImpl erweitert und zu allen zu modifizierenden Nachrichten wird die entsprechende Methode implementiert.
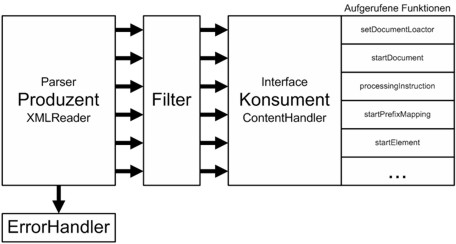 |
| Abb. 4.5 Struktur von SAX mit Filter |
import org.xml.sax.helpers.XMLFilterImpl Abb. 4.6 Beispiel eines Filters
public class TestFilter extends XMLFilterImpl
{
public void processingInstruction(String target, String data) throws
SAXException
{
//Verarbeitungsanweisung wird so blockiert
}
}
Beispiel 4.6 zeigt einen Filter, der alle Verarbeitungsanweisungen blockiert. Da dies die einzige implementierte Methode ist, werden alle anderen Informationen unverändert durchgeleitet.
filter = new TestFilter(); Abb. 4.7 Beispiel eines Filteraufrufs
filter.setParent(XMLReaderFactory.createXMLReader( "org.apache.xerces.parsers.SAXParser"));
filter.setContentHandler(new myContentHandler());
filter.parse("test.xml");