Eine Datenbank dient wie es der Name schon sagt zum speichern von Daten. Nun kann man Daten natürlich auch anders speichern z.Bsp. in einer Datei. Der Vorteil von Datenbanken liegt aber darin, dass man die Daten strukturiert speichern und somit natürlich schneller wieder darauf zugreifen kann. Somit kann man allgemein sagen: "Eine Datenbank dient zum strukturierten speichern von Daten!".
Es gibt nun verschiedenen Möglichkeiten, wie man die Daten strukturiert (und dann speichert). Das älteste Modell ist das hierarchische. Hierbei wird jeder Datensatz zusammen mit allen von ihm abhängigegn Datensätzen, als eine Einheit betrachtet. Eine Datenbank besteht nun aus mehreren solchen Eiheten. Das heißt, will man etwas in die Datenbank speichern oder herausholen, muss man die Einheit kennen wo sich der entsprechende Datensatz befindet (bzw. gespeichert werden soll).
Das zweite Modell ist das Netzwerkmodell. Hier kann jeder Datensatz eine beliebige Anzahl von übergeordneten Datensätzen haben. Man spricht auch von n : m Beziehungen. Es entsteht also ein Netzwerk von Datensätzen. Diese Beiden Modelle findet man jedoch heutzutage kaum noch in Anwendung, sie wurden weitestgehend durch das relationale und objektrelatione Datenmodell verdrängt.
Das relationale Datenmodell entstand in den 70er Jahren. Relational bedeutet dabei nur, dass die Daten in Tabellenform abgespeichert werden und zwischen den einzelnen Tabellen Beziehungen bestehen.
Das objektrelationale Datenmodell kam dann in den 80er Jahren auf. Hier werden die Daten ebenfalls in Tabellenform gespeichert. Zusätzlich unterstützt diesen Modell jedoch mehr Typen. So kann man beispielsweise auch Bilder, Videos, Musik und andere Datentypen speichern. Das objektrelationale Modell baut sich stark auf die objektorientierte Programmierung auf, so kann man auch Struktur und Methoden der Daten selbst definieren.
Da eine Datenbank nur Sinn macht, wenn man die Daten strukturiert speichert gibt es logischer Weise ein paar Regeln die man beachten sollte um Redundanz (Doppel oder Mehrfacheinträge) und daraus folgende Permutationen oder Mutationsanomalien zu verhindern. Als erstes gibt es deswegen sogenannte Primärschlüssel. Jede Tabelle sollte einen Primärschlüssel haben, welcher als eindeutiger Idendifikator aller Datensätze in der Tabelle dient. Jeder Primärschlüssel in einer Tabelle kommt also nur einmal vor.
Wichtig sind auch die sogenannten Normalformen. Es gibt hier 3 Stück die das entstehen von Redundanzen weitestgehend unterbinden.
Die 1. Normalform besagt, dass jeder Datensatz in eine eigene Zeile der Tabelle gespeichert werden sollte und somit die einzelnen Spalten keine innere Struktur aufweisen. Diese Normalform dürfte jeder intuitiv anwenden.
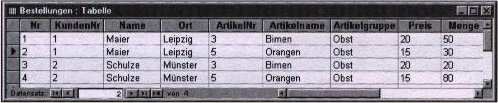
Die 2.Normalform besagt, dass in einer Tabelle nur Spalten enthalten sein sollen, die unbedingt nötig sind. Alles andere sollte in weitere Tabellen aufgeteilt werden.

Und die 3.Normalform besagt das sich in einer Tabelle nur Merkmale befinden sollten die untereinander unabhängig sind. Anderfalls sind die Merkmale ebenfalls in eine weitere Tabelle auszugliedern.
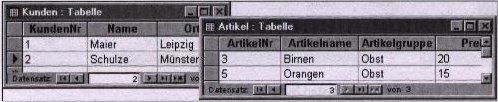
Wenn man es ganz weit treibt hat man am Ende nur noch Tabellen die aus 2 Spalten bestehen. Zum einen den Schlüssel und zum anderen ein Merkmal. Das ist natürlich nicht der Sinn der Normalformen. Es wird also schon etwas Fingerspitzengefühl benötigt um die Struktur der Datenbank sinnvoll zu gestalten.
Der Zugriff auf eine Datenbank erfolgt mit Hilfe von Abfragen. Ziel dieser Abfragen ist es natürlich mit möglichst wenigst Zugriffen einen Datensatz zu finden.
Realisiert wird das ganze über die Abfragesprache SQL(Structured Query Language). SQL ist eine descriptive/beschreibende Sprache. Mit anderen Worten man beschreibt was man gerne von der Datenbank ausgegeben haben möchte.
SQL unterstützt eine Menge von Befehlen. Der Großteil dieser Befehle wird auch von allen Datenbankherstellern unterstützt.
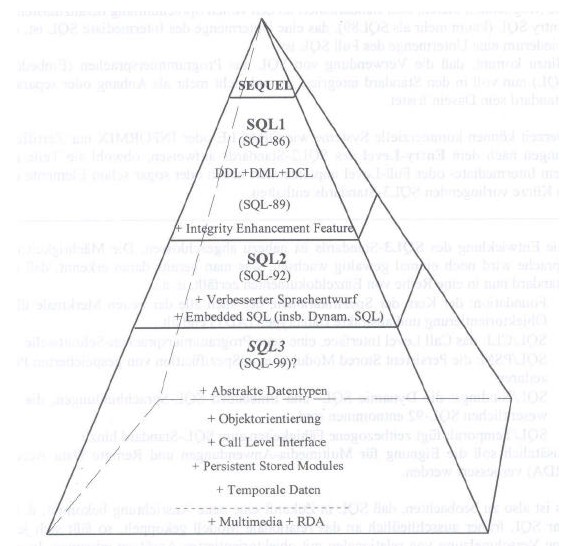
Zur Geschichte von SQL ist zu sagen, dass es Anfang der 70 Jahre mit dem Aufkommen der relationalen Datenmodellen von IBM entwickelt wurde. Es hieß ursprünglich SEQUEL wurde aber bald in SQL umbenannt.
1979 wurde SQL zum ersten Mal kommerziell von Oracle genutzt um den Zugriff auf ihr relationales Datenbansystem zu realisieren.
1986/87 kam es dann zur Standardisierung von SQL. Man sprach damals von SQL1, SQL86 oder SQL87.
1989 folgte dann eine Erweiterungder Integritätsbehandlung.
1992 definierte man den SQL2 bzw. SQL92 Standard. Hier kam es zur Erweiterung von vielen Funktionen z.Bsp. "dynamisches SQL" oder "normierte Views".
1999 wurde dann der SQL3 Standard festgelegt, dessen wesentlich Neuerung die objekt-orientierten Eigenschaften waren.
Hier eine kleine Grafik zur besseren Veranschaulichung :
Natürlich sind im Sprachumfang von SQL sehr viele Befehle enthalten. Ich wollte hier nur einmal ein paar wichtige nennen und kurz vorstellen.
| CREATE : |
Definition von Basistabellen Definition von Views |
| ALTER : | Tabellendefinition ändern |
| GRANT : | Autorisierung (Vergabe von Zugriffsrechten) |
| SELECT : | Zentrale Anweisung zur Datenauswahl |
| INSERT : | Hinzufügen von Zeilen |
| DELETE : | Löschen von Zeilen |
| UPDATE : | Verändern von Zeilen durch Änderung von Spalteninhalten |
Wie man sieht ist die Sprache SQL sehr logisch und einfach verständlich aufgebaut. Ein paar Tage (Stunden) dürften genügen um sich mit der Syntax und Semantik weitestgehend vertraut zu machen, so dass man zumindest einfache Abfragen realisieren kann.